This is amazing. One of my co-workers suggested I look at this data - the Enron email files - using our DataGravity storage appliance. So I downloaded and copied it to a CIFS share, extracted it, and now it was on our array.
So it took an hour or so to extract, but when it was done I made sure a DiscoveryPoint was taken and I went to File Analytics. This is what I found:
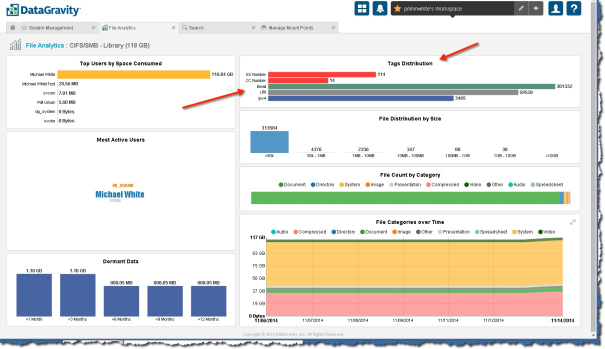
I am looking at the Tags Distribution. This means that while the writes are occurring - not in our primary IO path, but on our Intelligence controller, the Rules Engine is watching the writes for things we recognize and tagging them appropriately. So you can see above there is 301,332 instances of email addresses. Some might be false positives but it is still a very big number! Lots of Social Security Numbers and Credit card numbers too.
This comes out of the Enron emails that the government put into public domain. There is really a lot of data, but it still shows what can be easily found, without much work.
Literally I copied the gzip tarball to our array and extracted it, made sure the scheduled DP occurred, and switched to a web browser and select File Analytics followed by the Library Share and the screen you see above was there.
Would you not like to have this functionality yourself? Without installing or managing agents, or crawlers, or bots!
Update 11/14/14 1322 - if you want to learn more about where the emails came from here is some good info.
Michael
===END ===

Leave a Reply